


Understanding Large Language Models
The deep learning revolution, ChatGPT, and the race to AGI, product planning, geopolitics of semiconductors, user experience, jobs, events, and more

Welcome back to the Startup Pirate newsletter. The place on the internet to learn what matters in tech and startups with a Greek twist. In past issues, we dug into:
Not a subscriber? Come aboard and join 4,606 others.
Find me on LinkedIn or Twitter,
-Alex
Understanding Large Language Models
ChatGPT is a new category of product. It’s not just a better search engine, auto-complete, or something else we already knew.
Andrew Ng, professor at Stanford and co-founder of Google Brain and Coursera
Artificial intelligence is having its Cambrian explosion moment (although perhaps not its first). OpenAI's ChatGPT opened the public's appetite for what kind of problems AI can solve, going from 1m to 100m users in two months, while OpenAI's APIs captured developers’ imaginations and gave them the ability to build on top of its state-of-art models. This mass popularization on both levels already shows rapid innovation akin to the early days of iOS and Android apps. What made this wave possible? Large Language Models (LLMs); AI computer programs that can learn the characteristics of a language, predict and generate text.
I wanted to understand how LLMs work and what technological breakthroughs brought us here. Luckily, Rui Miguel Forte, a friend who has been building AI products and leading teams for years, was down to collaborate and write this piece together. Miguel is now the Director of Engineering (NLP/ML) at Causaly, a leading biomedical research platform leveraging AI to transform how humans find, visualize and collaborate on biomedical evidence, accelerating drug discovery and other development opportunities. Causaly is hiring here.
Let’s get to it.

The Deep Learning revolution
We have a new LLM pretty much once every few weeks. The current wave of large language models like GPT-4 (OpenAI), Bard (Google), LLaMa (Meta), etc., are all based on neural networks, a method in artificial intelligence that teaches computers to process data inspired by how humans do, learn from their mistakes and improve continuously without human assistance.
A manifestation of the exponential progress of neural networks in the past decade, which also made for a great documentary, was Google’s AlphaGo. Google DeepMind created a computer program with its own neural network that learned to play the board game Go, known for requiring sharp intellect and intuition. By playing against professional Go players, AlphaGo learned how to play at a level never seen before in AI and did so without being told when it should make a specific move. It caused quite a stir when it defeated multiple world-renowned masters of the game.

Such applications form a subset, and perhaps an evolution, of machine learning (where machines can learn and adapt from experience without being explicitly programmed) named deep learning to indicate the number of layers of the neural network. AlphaGo, ChatGPT, self-driving cars, etc. are all powered by large neural networks with multiple layers of basic computing units (the network's neurons), where each implements a relatively simple function of its inputs, but as a whole can solve complex computational problems. For example, let’s say we had a set of photos of pets and wanted to categorize them by “cat”, “dog”, and “hamster”. Deep learning algorithms can automatically learn visual features, such as the ears, which can then be used to distinguish each animal from another. In traditional machine learning, this hierarchy of features is established manually by a human expert and requires significant interference.
Three major factors led to the explosion of deep learning:
Advances in neural network algorithms: How we train and structure algorithms evolved significantly in recent years. The first field of AI where this progress was demonstrated was Computer Vision, which focuses on enabling computers to identify and understand objects and people in images and videos. It was in the early 2010s when a new type of neural network called Convolutional Network outperformed the state-of-the-art, at that time, by a significant margin and changed the game in machine learning.
Very large data resources are available: AI has gone from training on relatively small datasets to feeding deep learning models with massive corpora such as the entire Reddit, Wikipedia, IMDB databases, etc.
GPUs got more powerful: Training neural networks requires the same type of computations as computer graphics. For that reason, GPUs, which were initially popular among gamers, later became the “picks and shovels” of the AI gold rush, with NVIDIA dominating the market. We got better GPUs; therefore, we can now train larger neural networks.
Language Models: from n-grams to transformers
Predicting is difficult, especially about the future, as the old quip goes. But how about predicting something that seems much easier, like the next word someone will say? What word, for instance, is likely to follow “I looked up at the”? That’s a reductive description, but at the core, this is how ChatGPT replies to every human prompt. It can predict the next word in a sentence based on the large volume of text it has been cleverly trained on. Hence, ChatGPT’s strength is understanding language and generating words that read like human-written and sound right. In many cases, what sounds right will also actually be right, but not always (called “hallucination”, to use AI parlance).

The idea is not new. The early innings of statistical models that could predict the probability of a sequence of words were called n-grams (e.g. a 2-gram like “please turn” or 3-gram like “please turn your”) and were introduced in the late 1940s. You could estimate the probability of the last word of an n-gram given the previous words and assign probabilities to entire sequences of n-words. Of course, when looking at two or three words at a time, you had a very limited context in order to make an informed guess as to what word should come next. Although much simpler than LLMs, they were essential foundations for what would come next.
Fast forward several decades later, newer models could build a numerical representation of entire sentences and use that to predict either a label for that sentence — an example from the biomedical domain at Causaly: identify whether a sentence expresses a causal relationship between a drug and a disease (Yes/No) — or even new output sentences. What were the possible applications? Translate text into different languages, summarise paragraphs, automatically extract important entities from text such as product codes, answer questions given some text such as an FAQ, build chatbots for basic tasks, etc. But the results were often questionable, and the experience in many products was suboptimal. Something was missing.
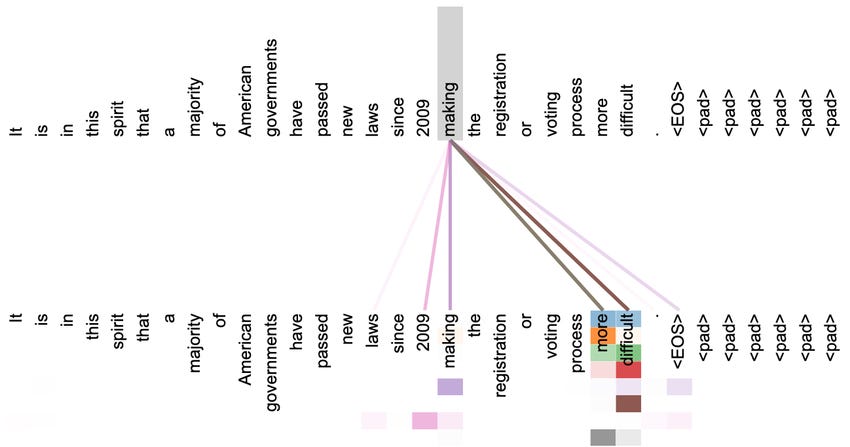
2017 was the turning point. In a seminal paper that year, “Attention is all you need”, written by a team at Google Brain, a novel neural network architecture, the Transformer, was introduced. For the first time, it enabled computers to process and train on larger datasets in lesser time and bring in the idea of “attention”, whereby the model could accurately understand the relationship between sequential elements (such as words) that are far from each other. Using attention, neural networks were significantly better (and faster!) at extracting the meaning of words in a sentence taking into account their position as well as the meaning of other words that could be far apart that modify them. In the diagram below, "making" is heavily modified by "more" and "difficult", which contribute significantly to the specific meaning of the verb "to make" in this sentence. The sequence of words "laws since 2009" is also important.
An explosion of LLMs and applications
People started to use transformers to build very large language models designed to process and generate text. Their number started to grow exponentially, with companies like Google and OpenAI leading the race. What probably changed the course of progress was a bold and expensive — the cost of training and serving these models is in the ballpark of several million $ — bet that OpenAI took with GPT-3.5 by creating an enormous model in terms of training text and layers of the neural network. It ended up with 175 billion connections between the different neurons. The bet paid off.
Hindsight is always 20/20, but before 2020 when GPT-3.5 was released, it wasn’t entirely apparent that increasing so much the size of the model would lead to such impressive results: writing like a great poet, developer, marketeer, politician, lawyer, you name it and replying to prompts with confidence (although oftentimes incorrect and mitigating against this is a major challenge of the road ahead). The successor of GPT-3.5, GPT-4, launched in March 2023, scored in the top ranks for at least 34 different tests of ability in fields as diverse as macroeconomics, writing, math, and, yes, vinology.
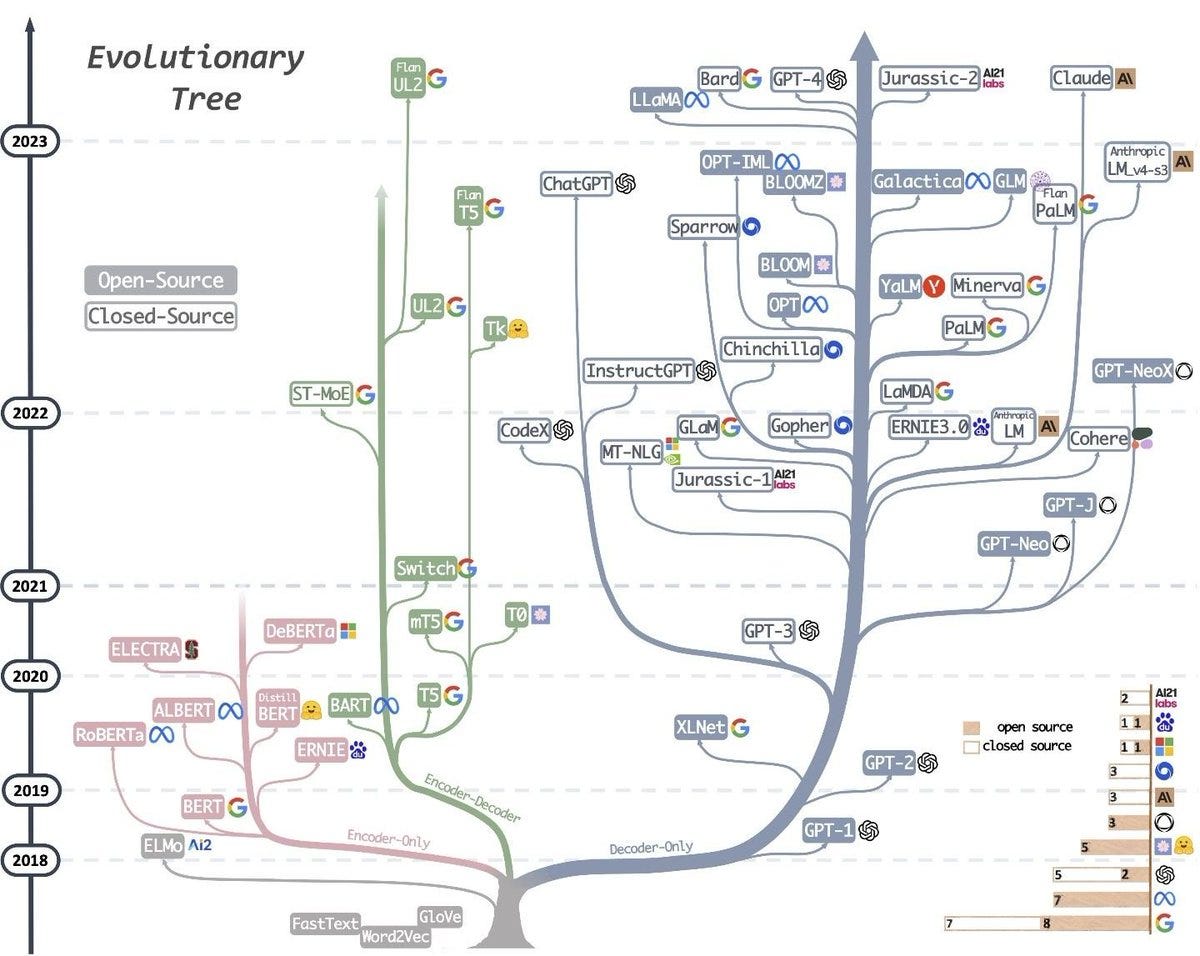
A number of big tech companies and startups went on to launch an LLM in the past two years. While many of them remain proprietary, there are plenty of open source models, leading to further popularization of applications with developers and product folks flocking to the space to test out novel concepts. It remains to be seen whether most applications will go through some variation of the following path, from a wrapper around Open AI’s APIs to fine-tuning open source models with their data to fit their particular use case or OpenAI’s aggressive movement down the pricing curve will foreclose any real economic opportunity for open source alternatives, ultimately starving them of resources (including user data).
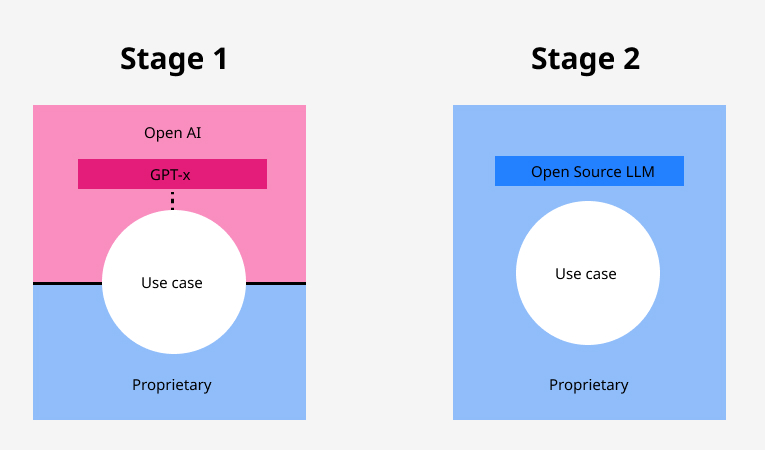
The latest hot experiment in the space is autonomous agents (like AutoGPT and BabyAGI), which are powered by LLMs and, in very simplified terms, can tell themselves what to do next without prompting from the user (like you would at ChatGPT) until a sequence of tasks is satisfied. e.g. find all YouTube videos about the Great Recession and distil the key points. One thing is certain, it's an exciting time to be in AI.
Do we need to slow down the race to AGI?
With machines being able to go through massive repositories of information and learn how to do: code, content, creativity, and everything in-between, there are oceans of considerations across AI safety, misinformation, propagation of false narratives, data privacy, economic value, and so on.
An open letter published earlier this year, titled “Pause Giant AI Experiments”, was signed by Elon Musk, Apple co-founder Steve Wozniak, engineers from Amazon, Google, Meta and Microsoft, and thousands of others to call for a pause in training AI systems more powerful than GPT-4 for at least six months, citing fears over the profound risks if they continue to be developed without regulatory scrutiny and shared safety protocols. Perhaps a close resemblance to how R&D in the hands of an intergovernmental organisation might look is CERN, which operates the largest particle physics laboratory in the world.
Are machines reaching Artificial General Intelligence (AGI), a point they are able to accomplish any intellectual task humans can do, and what would that mean for society and humanity? Most experts view the arrival of AGI as a historical and technological turning point akin to the splitting of the atom or the invention of the printing press.
We need other super important things too, but I think LLMs are part of the way to build AGI. To reach superintelligence, I think we will need to expand on the GPT paradigm in pretty important ways that we’re still missing ideas for. But I don’t know what those ideas are.
Sam Altman, CEO OpenAI
Though we are far from a superintelligent computer that learns and develops autonomously, understands its environment without supervision, and can transform the world around it, the nature of the technology means it’s exceptionally difficult to predict exactly when we will get there. And if we ever do, would it lean towards a means for humanity to “solve a lot of the big challenges facing society today, be that health, cures for diseases like Alzheimer, etc.” like Demis Hassabis, founder of DeepMind, said, or the “number one existential threat risk for this century, with an engineered biological pathogen coming a close second” as DeepMind’s chief scientist, Shane Legg, argued in 2011?
Recently, more and more people have started to call for increased AI alignment, a field of AI safety research that aims to ensure AI achieves desired outcomes and follows human intent. An example of the work alignment researchers did in the most recent version of GPT-4 was that they helped train OpenAI’s model to avoid answering potentially harmful questions. When asked how to self-harm or for advice on getting bigoted language past Twitter’s filters, the bot declined to answer. However, as indicated in the State of AI Report 2022, AI safety remains incredibly neglected, with an extremely low percentage of researchers compared to the broader AI field.
As a closing note, let’s see what the ultimate authority thinks:

Jobs
Check out job openings from Greek startups hiring in Greece, abroad, and remotely.
News
At Marathon, we led SMPnet's $1.4m Seed to enable real-time control of power grids with AI and edge computing, ensuring resilience and security of supply.
Next-gen video editing powered by AI, Runway, raised $100m Series D at a $1.5b valuation.
Automotive leasing FlexCar raised a new round (over $300m in total in the past two years in equity and debt).
ODAIA raised $25m Series B for its predictive analytics and commercial insights solution for life sciences.
GoCharlie AI raised $800k Seed for its generative AI for marketing.
EdTech startup Heroes Made received €300k investment.
Hewlett Packard Enterprise creating an R&D hub focusing on AI in Athens.
Entersoft acquired a majority stake in the HR tech startup SmartCV.
Resources
Kostas Mallios, Corporate Vice President at Applied Materials, on cultivating an entrepreneurial mindset, the geopolitics of semiconductors, and more. (link)
When will the code be ready? Expectations vs. Reality, by Nikos Vasileiou, CTO at Transifex. (link)
Time, slots, and the ordering of events in Ethereum Proof-of-Stake by Georgios Konstantopoulos, CTO at Paradigm. (link)
A comparison of Generative Adversarial Networks and Transformers by Matina Thomaidou, VP of Data Science at Dataseat. (link)
Systems design, user experience, and product onboarding by Dimitris Niavis, Lead UX Designer at WeatherXM. (link)
Events
“Open Coffee Athens #113” by Open Coffee Athens on May 12
“Key CX Insights from the 2 Biggest Marketplaces in GR” by CX Greece on May 18
“Open Coffee Thessaloniki #79” by Open Coffee Thessaloniki on May 22
“The power of documentation: From chaos to clarity” by Product Community Greece on May 23
“Munich Greeks in Tech” (May 24) and “Stockholm Greeks in Tech” (May 25) by Marathon VC
“Plum's Annual Pre-Summer Event” by Plum on May 24
“How web3 is shaking up a $5 trillion industry” by ath3ns on May 26
If you’re new to Startup Pirate, you can subscribe below.
Thanks for reading, and see you in two weeks!
P.S. If you’re enjoying this newsletter, share it with some friends or drop a like by clicking the buttons below ⤵️