
Intelligence Explosion: Part I
The path to AGI
This is Startup Pirate #108, a newsletter about technology, entrepreneurship, and startups every two weeks. Made in Greece. If you haven’t subscribed, join 6,500 readers by clicking below:
Intelligence Explosion: Part I
The following is Part I of our conversation with Aris Konstantinidis on artificial intelligence. Aris has worked for two leading AI labs, OpenAI and Cohere. At OpenAI, he was one of the first 100 employees and led business operations during the ChatGPT launch. We riffed together for 1:30 about his time at OpenAI, AGI, predictions about future LLM runs, AI safety, crafting a national AI strategy, Greece, and more. This is the first part, followed by Part II in two weeks. Let’s get to it.

Ari, you have worked for two of the leading AI companies of our time. What do you think was the aha moment for the general public that led to the massive acceleration of interest we see today?
AK: If I could pick two, I would say the releases of GPT-3 and ChatGPT. GPT-3 came in 2020, and it was a glimpse into the future. At the time, everyone was like, wow, LLMs are so great, and people were astonished by the progress. However, these models were just really bad. They couldn’t address any meaningful use cases. Then, even though ChatGPT in 2022 was based on existing models, the extra touches, which we can discuss later, made it so useful and intuitive. This shows that even with such very advanced technologies, how you build and serve a product can make a huge difference.
Give us some more colour about the roles you had at OpenAI.
AK: I did my undergraduate at Athens University of Economics & Business in Greece, where I co-founded an NGO startup that brought together volunteers, non-profits, and corporations. Then, I spent two years at PwC, and in 2017, I left to pursue an MBA at Stanford.
I joined OpenAI in 2019, the year they raised their first billion from Microsoft. I entered the interview process—the last interview was with Sam Altman, who used to interview every candidate back then—and joined as the first business operations person. We were around 100 people at that time.
I was a generalist for the first two years, running organisational planning, supporting the leadership team, and working on special projects. I was part of the cross-functional team that launched GPT-3, focusing on launch partnerships but doing all sorts of things, from setting up the first CRM to doing customer support shifts on Intercom. It felt like working at a super early-stage startup with lots of funding. While the Go-To-Market function was built up, I helped set up the revenue operations tech stack.
Around that time, I closed OpenAI’s first strategic data partnership, which enabled us to train and commercialise Dall-E 2. Then, at the beginning of 2022 (the year we launched ChatGPT), our COO (my manager at the time) asked me to drop everything I was doing and focus on operationalising and scaling up the Human Data function. As part of that, I worked super closely with the team that launched ChatGPT and managed some of their data pipelines.
Very few companies have experienced successful product launches of that magnitude. What was it like in the days close to the ChatGPT launch?
AK: Intense! All product launches at OpenAI are intense. When a timeline and launch plan is set, everyone commits. There’s rarely a reason why a launch date is delayed—it must be something critical, such as safety-related. But the talent density is so high that there aren’t many problems a team like that cannot address. During the ChatGPT launch, it was certainly chaotic. If you look at the GPT-4 paper, you will see hundreds of contributors. That shows how huge this company-wide effort was and how many teams had to come together to make it happen.
Going from GPT-3 to GPT-4 was like going from toddler-level to a smart high schooler. What were the main technological breakthroughs that led to that?
AK: As you think about improving model performance, there are three key pillars:
Algorithmic & architecture improvements. Researchers develop better ways of distilling knowledge, using bigger context, achieving efficiencies, cleaning out the data, etc.
More and better data. You can acquire more public and private data to create the base model. Then, there is also human-generated or synthetic data for the post-training phase, which typically involves fine-tuning the base model on targeted data sets to instil desirable behaviours into the model. This process of improving model performance, called Reinforcement Learning from Human Feedback (RLHF), was critical towards training ChatGPT.
Compute. Access to more compute power allows you to train bigger models with more parameters and for more extended periods, which also boosts performance.
To get from GPT-3 to GPT-4, we had to make improvements across all these three axes. I was closely involved with the data side. ChatGPT was trained on human feedback. We worked with hundreds of human contractors demonstrating desirable behaviours to AI (supervised fine-tuning and preference data). We had humans chat with our AI models and/or rank the AI responses to generate preference data, etc. We used reinforcement learning algorithms on top of that data to train the models to be good in these kinds of interactions. That’s how we went from GPT-3 (which essentially did pattern matching and didn’t understand the intent of the user questions) to ChatGPT, which was much better at following instructions and acting as a helpful assistant.
What was the big difference in the philosophy between OpenAI and Cohere?
AK: I joined Cohere in 2023 as a founding member of the strategy & business operations team. My role was more strategic than my role at OpenAI. Back then, Cohere was the only LLM company focusing on enterprise. After the ChatGPT launch, for months, you would see cool demos on Twitter but only a few impactful applications, and that was frustrating to me. Cohere bet on large enterprises paving the way for more impactful use cases (because they have the resources, talent, and user base). And, in retrospect, that was directionally the right move. We now see OpenAI, Anthropic, and others focusing on enterprise, with many companies already moving LLM applications into production. But we still barely scratch the surface of what’s possible.
OpenAI is more focused on building AGI to benefit humanity, while Cohere is thinking about the problems we can solve for enterprises and people today using the existing technology. Even though building AGI was and still is extremely interesting and exciting to me, I found Cohere’s approach refreshing at the time. It helped me understand the challenges companies face today and what we can do to address them.
What do you think about the co-existence of open and closed source models?
AK: Open source models are great and help democratise access, with the entire community contributing to improving them. I believe proprietary models have an edge, and that’s not easy to change. Meta is making huge investments in open source, but how long will they keep throwing money at this? I don’t doubt investments and participation at a large scale in open source will continue, yet likely, questions around the sustainability of this business model will soon arise.
At the same time, governments are pushing towards transparency (towards which open source can help). We want to know how these models are trained, what data they are trained on, etc. Ethics and safety are increasingly important. Hence, in the near term, close models will continue to have an edge, but ultimately, we might end up with a hybrid state where the base models are open source, and additional customisations are closed source, or there’s a mix of open source and closed source models that coexist for different use cases. It’s hard to imagine a near-term future where everything is open source.
You said you’re passionate about AGI. What does Artificial General Intelligence mean to you? And what’s your sense about the trajectory we are in right now?
AK: Every year at OpenAI, we would have this internal survey asking employees when they think we would build AGI. Our definition of AGI was highly autonomous systems that outperform humans at the most economically valuable tasks; systems that can match or exceed human performance in most things, reason, plan, etc.
Since joining OpenAI, my prediction has always been that we will get there by 2030. I haven’t changed my mind, but it’s essential to understand that AGI is not a single state; it’s more of a spectrum with multiple levels. We can build AGI that surpasses human performance in most tasks, but that’s not the same as the Superintelligence people see in sci-fi movies.
There is valid scepticism around whether we can actually build AGI, which partially stems from the fact that models today still don’t demonstrate great reasoning or common sense. They continue to make silly mistakes, which implies they can’t fully reason or understand the world yet. While I think we can reach AGI by continuing to scale the existing deep learning approaches (but still, we’d need at least one or two more big breakthroughs to make that happen), we may end up discovering better paths—perhaps something related to symbolic AI, or ways to create world models without human labelling involved.
It generally feels like something is still missing in figuring out the cognitive aspect of intelligence. I’m optimistic that we will figure out these breakthroughs in the next few years and be able to reach AGI by 2030.
What do you think happens on the next major training run for LLMs?
AK: There are three things I’m excited about for the next couple of years:
Getting better multi-modal models. These models can use modalities like text-to-image, image-to-video, text-to-video, etc. We’re already getting better multi-modal models as compute becomes cheaper.
Models with better reasoning abilities. We have this new paradigm now with the o1 model by OpenAI, which shows that if we leverage more compute at inference time—in other words, if we allow the models to spend more time “thinking”—it helps improve their reasoning and problem-solving abilities. You can think of it as giving a student limited time to answer each math question. They can solve easy questions quickly and move on. But for harder questions, this won’t be enough. However, if we allow the student to spend a little extra time checking their work, trying different approaches, and ensuring their answers are correct, then they could tackle more difficult math questions, too. In the same way, the o1 model spends more "time" (inference compute) on difficult or complex questions, allowing it to think through multiple possibilities before responding. This paradigm is promising, and we will see more labs follow suit.
Agentic AI. We already have simple AI agents that can summarise conversations, respond to customer requests, add items to your cart, etc. Nevertheless, the game changer will be when we have AI agents that can plan, perform more meaningful actions, and complete complex tasks end-to-end. This will be the first step towards AI agents working together (and alongside humans) to solve complex problems. Each agent will specialise in a particular area, and there will be an orchestration layer to achieve coordination.
Stay tuned for Part II, where Aris and I chat about AI safety, compute as currency, building a national AI strategy, the case of Greece, and more.
Jobs
Check out job openings here from startups hiring in Greece.
News
Phylax Systems (security for crypto) announced a $4.5m Pre-Seed.
Embio Diagnostics (rapid diagnostics) raised €2.5m.
EVO HUMAN PERFORMANCE (sports performance) raised €1.2m Seed from Unifund.
MintNeuro (semiconductors for neural implants) raised £1m Seed.
Indeex (digital twins for F&B) raised €1 Seed from Unifund and TECS Capital.
Swarm Aero (UAV swarm) secured a Seed round from Founders Fund, Coatue and Khosla.
Voda AI (AI for water utilities) secured funding from L-Stone Capital.
Workorb (AI for AEC industries) secured Seed funding led by Metavallon VC.
Resources
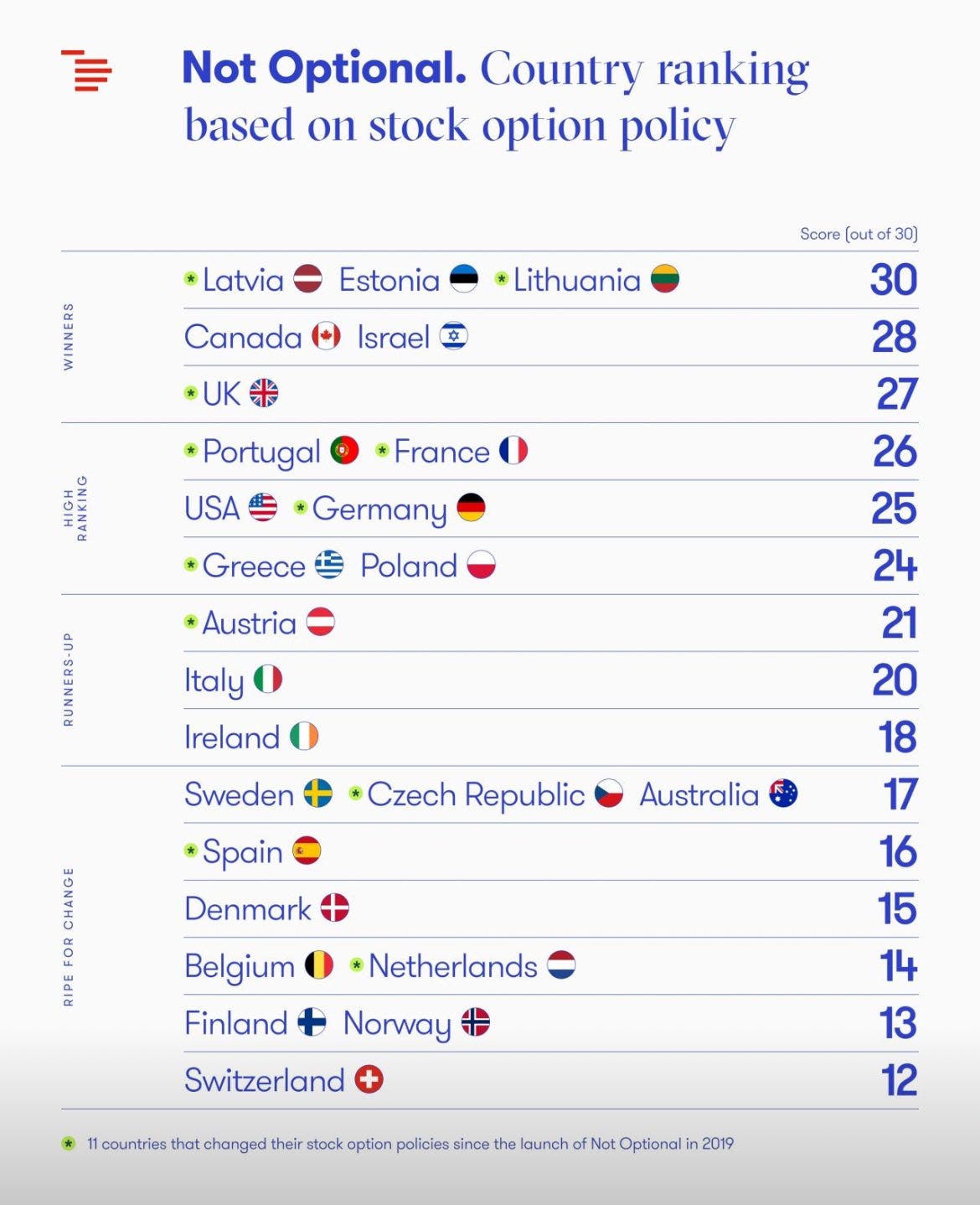
Greece has one of the most attractive policies for stock options across Europe. Best resource for how options are treated here.
Leveraging photonics to address AI’s energy consumption with George Zervas, co-founder & CTO at Oriole Networks.
Revolutionising corporate learning with Lefteris Ntouanoglou, founder & CEO at Schoox.
New podcast on SaaS and entrepreneurship with Kostas Livieratos, founder of Schedul Threads, and Stefanos Athanasoulias, Frontend Engineer at eShare.
Nicky Goulimis, co-founder of Tunic Pay, shared her journey in fintech.
Faster data imports in deployment previews with Nick Nikitas, Senior Platform Engineer at Blueground.
More about Greece and nuclear energy.
Events
We’re hosting Greeks in Tech in Amsterdam on Dec 4. Join us here!
“GenAI Summit” on Nov 18
“How to start a global startup from Greece” by Founder Institute on Nov 19
“Build images securely and publish compose stacks” by Docker Athens on Nov 19
“Tech recruitment meetup in Athens” by WE LEAD on Nov 21
“Kubernetes Athens vol25” by Athens Kubernetes on Nov 22
“3rd Skill Up Forum” by Envolve and linq on Nov 22
“Thriving in an AI-Driven future” by La French Tech Athens on Nov 27
“Greeks at Hamburg in Tech #0” on Nov 28
“WebDriver Bidi & Playwright with AI” by MoT Athens on Nov 28
“Leading effective board meetings” by Tech Finance Network on Dec 11
Thanks for reading, and see you in two weeks. If you’re enjoying this newsletter, share it with some friends or drop a like by clicking below ⤵️
Thank you so much for reading,
Alex
Aris is such a cool guy! I remember him being friendly and vividly presenting us for more than 3 hours what OpenAI does (pre-ChatGPT era) and he was glad to take as many questions as possible 🙌